Natural Language Interfaces to Databases (NLIDB)

This article presents an overview the history of this field and describes some recent and less recent attempts at natural language interfaces to databases.
Definition
A natural language interface to a database (NLIDB) is a system that allows the user to access information stored in a database by typing requests expressed in some natural language (e.g. English), or a subset of natural language.
History
Early attempts (60’s)
First attempts of language interfaces to databases appeared as early as the sixties. An example of such a system is LUNAR (Link to Author’s page), designed to provide answers to naturally written questions about the geological analysis of lunar rocks returned by the Apollo missions (able to answer questions such as which rock contains magnesium?).
Another such system is LADDER which could be used with large databases and could be configured to interface different databases. LADDER used semantic grammars (see below), which required elaboration of a specific grammar for each database.
In the mid-eighties NLIDB were a very popular area of research, and efforts were precisely focused on portability issues and on developing generic interfaces that could be easily adapted to various databases. A well-known system from these times is CHAT-80, which was implemented entirely in Prolog.
Failed promise
Despite the interest and numerous attempts, NLIDBs did not gain the expected rapid and wide commercial acceptance. In 1985, Ovum Ltd. was foreseeing that “By 1987 a natural language interface should be a standard option for users of DBMS”. Instead, most of the commercial products have been discontinued due to their poor performance and the difficulty for porting and configuring them.
Some examples of such failures from prominent vendors are: LanguageAccess, discontinued by IBM, English Query (see below for a detailed description) developed by Microsoft and included for the last time in SQL Server ver. 8.0 in 2000, and English Wizard (by Linguistic Technology Corporation) which was discontinued years ago. ELF (reputed as being one of the best NLIDBs and still available for sell, see their report as well) no longer provides technical support and has not been updated for many years.
The development of successful alternatives to NLIDBs (most notably user interfaces) and the intrinsic problems of NLIDBs (discussed below) are probably the main reasons for the lack of acceptance.
Rebirth of AI (2015’s)
We are now seeing a rebirth of interest for natural language processing, albeit in a somewhat different form. On the one hand, probably due to the boom of mobile computing, chat and advances in speech processing, we are now seeing bots (aka. conversational agents) becoming popular, taking advantage of connected services to carry out tasks. On the other hand, ubiquity of search-like interfaces made popular by internet search engines call for the refinement of such search experiences. Search applications have become very interactive, with smart contextual suggestions, some degree of comprehension, and fast as-you-type updates which provide continuous guidance.
People are now used to formulating their information needs using keywords and browsing through results, and iteratively converging onto what they are looking for. Related information revealed while seeking the answer is itself often valuable and is even expected by users. Who hasn’t changed their mind after googling some provider and thus finding out about another? It is indeed no longer a question of providing a unique and correct answer to a perfectly formulated and unambiguous question, but rather act as an “information guide”, a sort of smart assistant in the presence of unclear needs and vast amounts of data.
It no longer a question of providing a unique and correct answer to a perfectly formulated and unambiguous question, but rather act as an “information guide”, a sort of smart assistant in the presence of unclear needs and vast amounts of data.
Legacy system example: English Query (SQL Server) - 1996 to 2003
History
English Query first shipped with MS SQL Server 6.5, in 1996 (20 years ago!). It was progressively improved throughout version 8.0, then was later abandonned, reportedly due to lack of customer interest. It never supported other languages.
Features
English Query harnesses a natural language engine able to interpret sentences and process them into SQL queries that are sent to SQL Server for processing.
For instance, the following sentences:
Show me a list of all the customers in my database
Are there any customers?
Give me a complete list of my customers, please.
List all customers.
Customers.
All produce the same query:
Select CustomerID from Customers
Operators
English Query can generate SQL operations as well:
| SQL operator | |
|---|---|
| How many customers are there? How many customers have not rented movies this month? | sum() |
| Which is the oldest store? What is the latest date that a person rented the movie “Full Metal Jacket”? | min() or max() |
| What is the average age of people who rented movies directed by Stanley Kubrick? | avg() |
| How many movies for each customer? What is the average number of rentals per customer? | groupBy() |
Contextual information
It can remember the previous results and use those to interpret follow-up questions:
Who rented movies in the last 30 days?
How many were science fiction?
Of those, which movies were directed by Stanley Kubrick?
Which of those had a running time over two hours?
Configuration
English Query requires some additional configuration in the form of definitions:
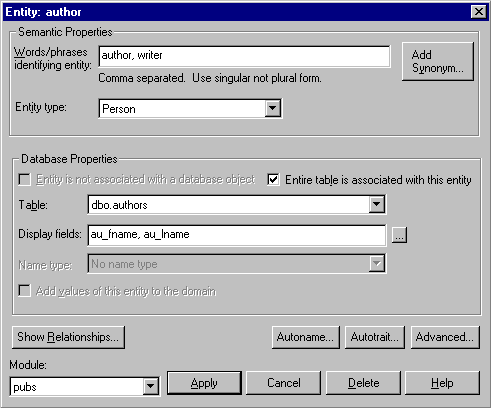
- Entities: noun-object that can be referenced in the database (tables or columns). Example: customer, author
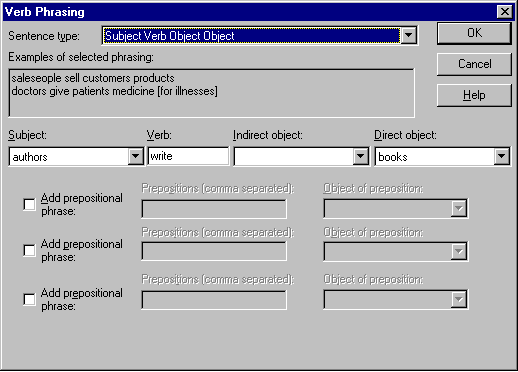
- Relationships: how entities relate to each other. Relationships are defined using certain phrasings:
- Prepositional phrasing, e.g. “from” (
which customers are from NY?) - Verb phrasing, e.g. ”bought” (
Who bought oranges last month?) - Adjective phrasing: adjectives that describe traits of the entities e.g. “young” (
Which movies were bought by young customers?) - Trait phrasing: relationship between a table and its columns (
List customer address and age) - Subset phrasing: categorization of entities (
Which movies are science fiction?,Who rented romances or dramas?)
- Prepositional phrasing, e.g. “from” (
- Synonyms: additional synonyms to those of the english language
Challenges
NLIDB are riddled with a number of fundamental challenges that explain the relative scarcity of successful products in this area.
“Empty prompt” problem (aka habitability problem)
It is in fact basically unsettling to find oneself in front of an empty prompt. In relevant literature, this also referred to as the “habitability problem”. Users need some kind of guidance as to where to start, what to ask, and need to develop an understanding about what’s possible to ask.
Uncertain linguistic coverage
Related to the previous point, a frequent complaint against NLIDBs is that the system’s linguistic capabilities are not obvious to the user. Users find it difficult to understand and remember what kinds of questions the NLIDB supports.
For example, the MASQUE system is able to understand What are the capitals of the countries bordering the Baltic and bordering Sweden? This leads the user to assume that the system can handle all kinds of conjunctions (false positive expectation). But it will reject What are the capitals of the countries bordering the Baltic and Sweden?
Similarly, a failure to answer a particular query can lead the user to underestimate the system (false negative expectation).
Linguistic vs. conceptual failure
When the NLIDB cannot understand a question, it often not clear to the user whether the rejected question is outside the system’s linguistic coverage, or whether it is outside the system’s conceptual coverage. Thus, users often try to rephrase questions referring to concepts the system does not know.
Similarly, users can also give up rephrasing questions that the system could actually handle from a database standpoint.
Users assume intelligence
NLIDB users are often misled by the system’s ability to process natural language, and they assume that the system is intelligent, that it has common sense, or that it can deduce facts.
Inappropriate medium
Outside of the speech domain, it has been argued that natural language is not an appropriate medium for communicating with a computer system. NLIBDB users have to type long questions, and natural language questions are also often ambiguous.
Linguistic problems
- Modifier attachment: The query
List all employees in the company with a driving licenseis ambiguous unless you know that companies can’t have driving licenses. Similarly,List all employees in the division making shoescould mean different things depending on the domain. - Conjuction and disjunction:
List all applicants who live in California and Arizonais ambiguous unless you know that a person can’t live in two places at once. - Nominal compound:
City departmentcould denote a department located in a city, or a department responsible for a city.Research departmentis probably a department carrying out research, whereasresearch systemis probably a system used in research. - Anaphora: Resolve what a user means by
he,she, oritin a self-referential query. - Extra-grammatical utterances: Every-day language often contains syntactically ill-formed input, telegraphic utterances, typos etc.
Techniques
Pattern-matching systems
Early NLIDBs relied on pattern-matching techniques to answer questions. For instance, consider a database table holding information about countries:
| Country | Capital |
|---|---|
| France | Paris |
| Italy | Rome |
A primitive pattern-matching system could use rules like:
pattern: ... "capital" ...` => report capital of row where country
pattern: ... "capital" ... "country"` => report capital and country of each row
Thus if the user types What is the capital of Italy?, by following the first rule the system can report Rome. The same rule allows the system to handle Print the capital of Italy, Could you tell me what is the capital of Italy?, etc.
According to the second rule, any request containing the word capital followed by the word country should be handled by printing the capital of each country. So for instance it supports What is the capital of each country?, List the capital of every country, etc. After getting used to the system, the user would probably get a sense for the rules behind and use only e.g. capital France because it’s much faster to type.
Despite its simplicity, this approach has been shown to handle a surprisingly broad type of queries, e.g. in this illustrative case it could even give a reasonable answer to Is it true that the capital of each country is Athens? by simply listing the countries and their capitals as some sort of indirect “negative” answer.
In fact, modern conversational agents such as Cortana follow a similar principle, although rules are not deterministic but based on statistical training (logistic regression classifier of intent). This allows them to support may forms of formulating an intent. For instance, if in the training set the presence of the “flight” word unambiguously indicates an intent of booking a flight, the system will perform remarkably well whenever that word is present anywhere in the sentence.
Syntax-based systems
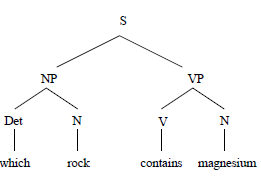
In syntax-based systems the user’s question is parsed into a syntax tree. A grammar describes the possible syntactic structures of the user’s questions. For instance, below the simplistic grammar in a LUNAR-like system (mentioned above)
Sentence -> NounPhrase VerbPhrase
NounPhrase -> Determiner Noun
Determiner -> "what" | "which"
Noun -> "rock" | "specimen" | "magnesium" | "radiation" | "light"
VerbPhrase -> Verb Noun
Verb -> "contains" | "emits"
Using this grammar, a NLIDB could figure out that the syntactic structure of the question Which rock contains magnesium?
The NLIDB could then map this tree to the following programmatic database query (X is a variable):
foreach X where is_rock(X)
if (contains(X, magnesium))
print(X)
This mapping would be carried out by rules:
"which" => foreach X where
"rock" => is_rock(X)
NounPhrase => Determiner Noun
...
Where Determiner and Noun are the mappings of the determiner and the noun respectively. Thus the mapping of the NP sub-tree in our example would be
foreach X where is_rock(X)
Syntax-based NLIDB usually interface application-specific database systems that provide database languages carefully designed to facilitate the mapping from the parse tree to the database query.
Semantic grammar systems
In semantic grammar systems, the question-answering is still done by parsing the input and mapping the parse tree to a dabase query. The only difference is that the grammar categories do not necessarily correspond to syntactic concepts. Here’s a possible semantic grammar for the same domain:
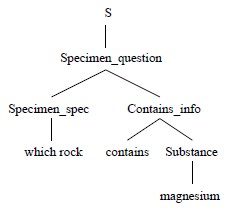
Notice that some of the categories of this grammar (e.g. Substance, Specimen_question) do not correspond to syntactic constituents (e.g. noun, sentence). In such a way, semantic information about the knowledge domain is hard-wired into grammar, allowing to enforce semantic constraints on the type of supported queries. Systems using such grammars are naturally highly domain-specific.
Intermediate representation portable systems
In systems that attempt cross-domain applicability, queries are transformed from the parse tree into an intermediate logic query, using e.g. semantic rules similar to the mapping rules described above (or a graph-maximization algorithm in the PRECISE system, see below for a more detailed presentation).
In the MASQUE (Prolog-based) system, the question What is the capital of each country bordering Greece? would be mapped to the following logical query:
answer(Capital, Country) :- is_country(Country), borders(Country, "greece"), capital_of(Capital, Country)
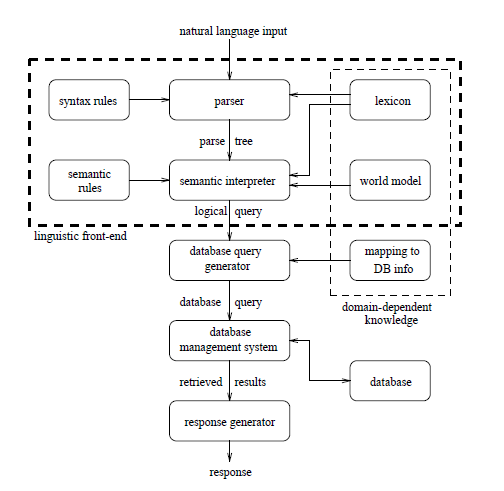
This logical query expresses the meaning of the question in terms of high-level concepts. It states that the meaning of the user’s question is to find all pairs (Capital, Country) such that Country is a country, Country borders Greece, and Capital is the capital of Country. The semantic interpreter also consults a world model, which defines a hierarchy of classes of objects. This hierarchy is used in combination with typed constraints on predicate arguments, which specify the classes to which the arguments of a particular logic predicate may belong. These constraints help in assessing the validity of generated logical queries, and in selecting the right one in case of ambiguity.
The logical query does not refer to database objects (e.g. tables, columns) and it does not specify how to search the database. In order to retrieve the requested information, it has to be transformed by a database query generator, using mapping to database information. The database mapping information specifies how logic predicates relate to database objects. For the example above, the mapping information for the is_country predicate could be:
SELECT country FROM countries_table
System example: PRECISE
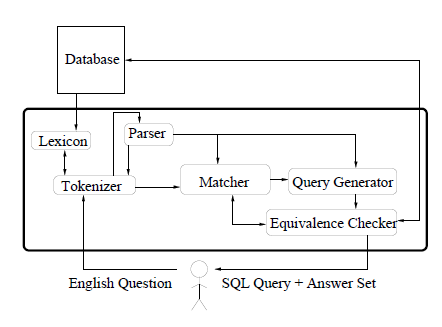
The PRECISE system (2003) is considered one of the best of NLIDB ever developed. It is an interesting system as it combines semantic and statistical approaches to achieve complete database independence, with no training nor configuration required. In addition, it has been shown to achieve much better recall and precision than English Query.
A natural language question such as What are the Paul Mazursky films with Woody Allen? is first mapped to a complete tokenization of the question. The tokenizer proceeds by stemming (finding the root) of each word in the question, and looking up in the lexicon the set of database elements it could potentially participate in (the lexicon relies on WordNet lexical database to identify synonyms).
The statistical parser extracts parts-of-speech tags and attachment relationships between words, which are fed back into the tokenizer to create multi-word tokens (e.g. jobs requiring five years or more of programming experience can yield the token require experience). Attachments are also used by in the matching stage to reduce ambiguity, together with a graph matching algorithm to find the most appropriate matching of tokens to database elements.
These matchings are then used by the query generator to formulate the SQL query. The equivalence checker tests whether there are multiple distinct solutions to the matching problem and whether these solutions translate into different SQL queries, and if so declares the query as ambiguous.
System example: NaLIR (2014)
The NaLIR system (see also here for more details) is a relatively recent attempt at a generic NLIDB, proof that this is still a tempting topic of research. It relies on some degree of user feedback to resolve ambiguous interpretations:

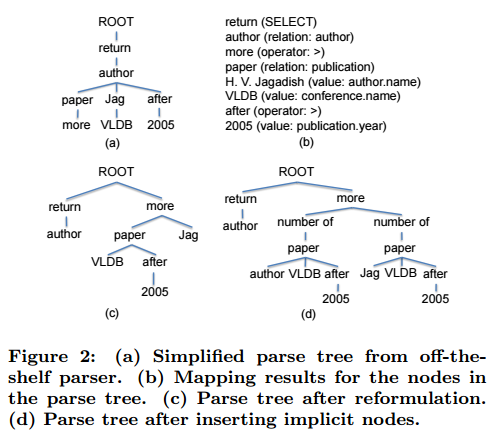
From the linguistic parse tree (parsed using the Standford parser), it generates a so-called Query Tree which is a formal intermediate representation of the query, defined with a specific grammar.
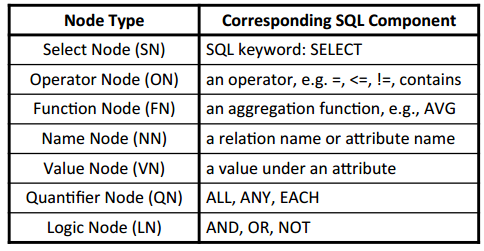

Linguistic nodes are mapped to such query tree nodes using a mapping algorithm (which relies on the database schema). The resulting tree is evaluated for compliance with the grammar, and in case of invalidity an optimization algorithm is run to adapt the tree towards a valid solution.
Alternative solutions to this problem are scored and presented to the user so that he can decide of the final interpretation (the query tree indeed allows for reformulation in understandable natural language). Missing implicit nodes arising from the relationships (such as number of required by the more relationship) can also be validated by the user.
Menu-based systems
Due to the challenges met with NLIDB there have been attempts to develop more constrained querying interactions. For instance, menu-based systems do not allow the user to type directly any type of question. Instead, each question has to be constructed by choosing possible words or phrases from menus or via “autocomplete” mechanisms. This ensures that every query can be answered and removes any ambiguity, as well as guides and informs the user as to what the system supports.
One of the first examples of such a system is the NLMENU system, developed in the early eighties. Here’s the initial screen:
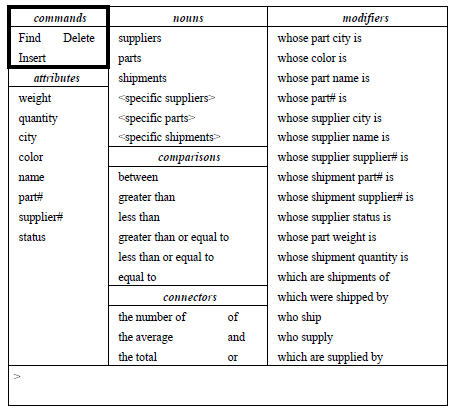
After Find has been selected, the attributes, nouns and connectors menus become activated. The user selects color, and the question becomes Find color. In a similar manner, the user then selects and, name, of and parts. At this stage, the screen becomes:
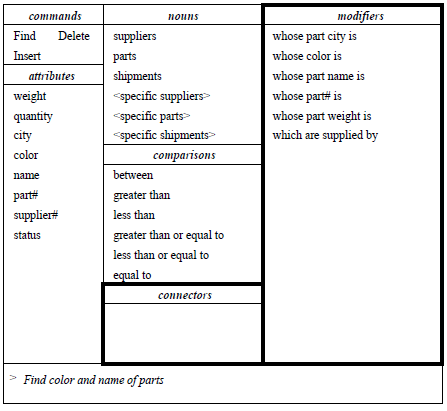
The user selects whose color is from the modifiers menu, and the question becomes Find color and name of parts whose color is. At this point, a special menu appears, listing the possible colors. After selecting a color (e.g. red), the question is complete. NLMENU uses a semantic grammar. Whenever a new word or phrase is selected, the system parses the sentence assembled so far, and processes the grammar to determine the words/phrases that can be attached to the existing partial sentence to form a sentence the system can understand.
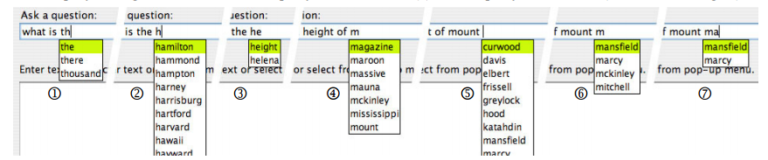
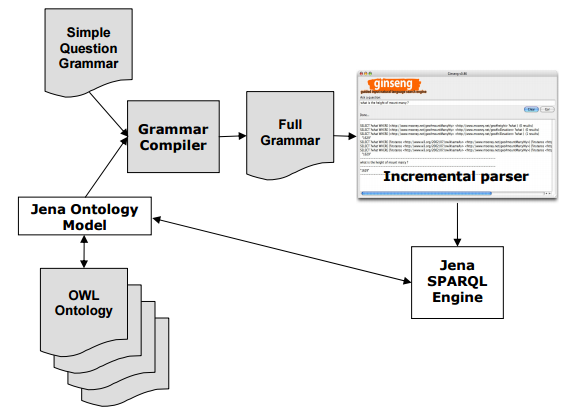
A more recent example of a similar approach is the Ginseng search engine (2006), developed at the University of Zurich in the context of the Semantic Web. Ginseng stands for guided input natural language search engine. Ginseng uses a small static grammar that is dynamically extended with elements from the loaded ontologies and allows easyextension to new ontologies. When the user enters a sentence, an incremental parser offers possible continuations of a user’s entry by presenting the user with drop-downs:
Modern systems
Below are some examples of recent developments in the field of database interfaces in the analytics and business intelligence market. These modern systems offer a search-like exploration interface with autocomplete which google has made familiar.
Thoughtspot (founded in 2012, raised 90$M)
Thoughtspot offers a flexible querying front-end for business intelligence data. It supports integrating data from various sources and understands the underlying schemas and relationships, thus requiring no additional modeling. Data can be explored using a search box with autocompletion and suggestions, and it dynamically shows results with automatic plots and various forms of graphs, as can be seen below:
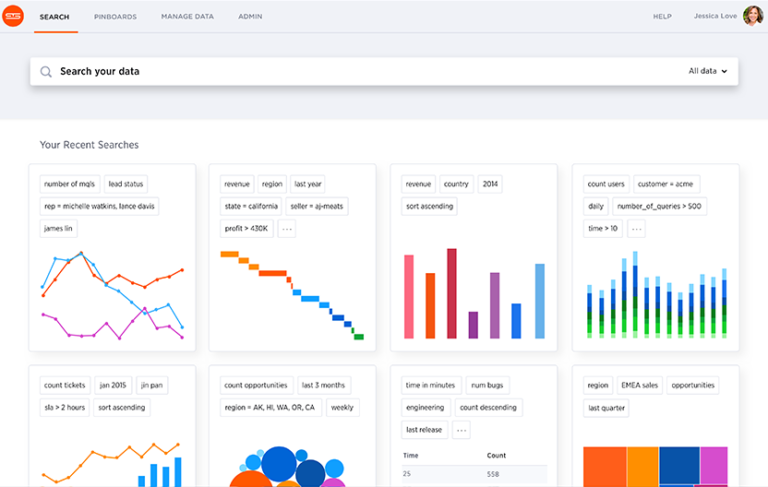
The algorithms that calculate and rank the completions in the search box take into account factors such as how often a word shows up in the data (its cardinality) and how often people have searched for it. Prefix, suffix and substring matches are supported, and it also looks for synonyms. The engine also offers suggestions based on spellcheck and phonetic matching algorithms (metaphone) for more robust entry handling. Only the entities the user is allowed to see are visible in the search suggestions. The interface also recognizes common aggregate functions such as “sum” or “standard deviation”, and computations such as “growth of” that are complex to express in a formal language like SQL.
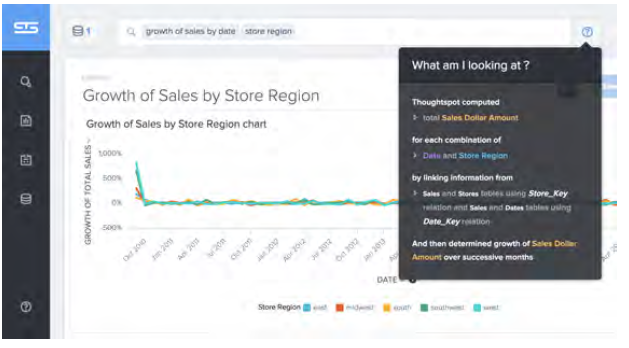
A button next to the search box lets the user translate the search string to a form that explains how the different tables were joined, what filters were applied, and what final result was computed:
Arimo (founded in 2012, raised 13$M)
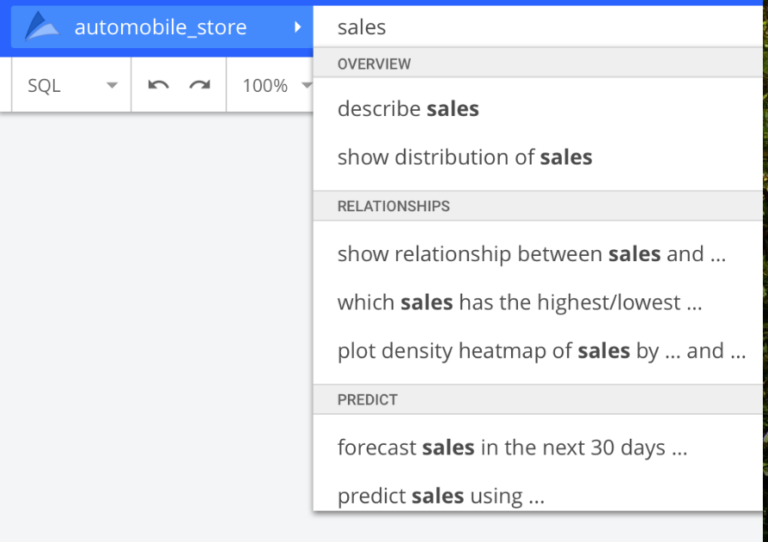
Arimo is a BI system based on the notion of “narrative”. Its interface allows building documents where data is embedded next to editable text. Its search UI is more oriented towards NLP, apparently using “customizable grammars”. As can be seen below, an interesting feature of the completion drop-down is the organization of suggestions in categories:
Power BI (2015, Microsoft)
Power BI is Microsoft’s take on this market. It offers a mixed user interface with both natural language support and autocompletion boxes, as well as form-based query construction:
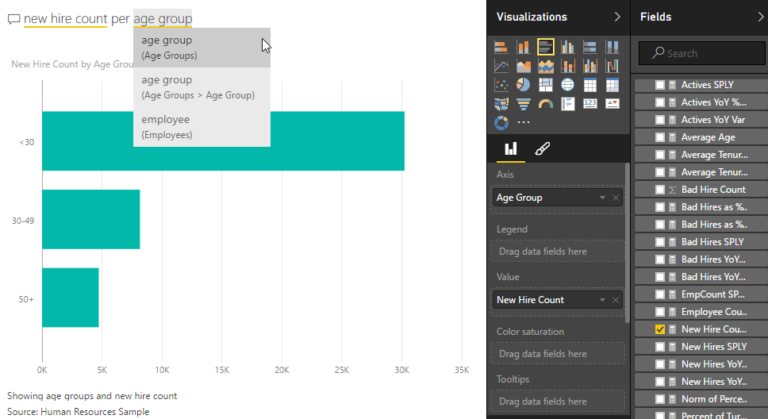
Unfortunately, in our small test it turns out to be difficult to use. The variety of means of entry makes the experience somewhat confusing, and it suffers from bugs like the completion menu not showing up, offering wrong suggestions, sometimes gettings stuck, and it’s hard to find what can be expressed.
SimpleQL (founded in 2013, funding unknown)
It seems like the dream of a natural language interface for SQL databases is still alive, and proof of that is SimpleQL with their Kueri system. However here again the problem is a framed a little differently than in the past: the experience is indeed closer to a search experience, with an elaborate suggestion box guiding the user to formulate queries that the database supports:
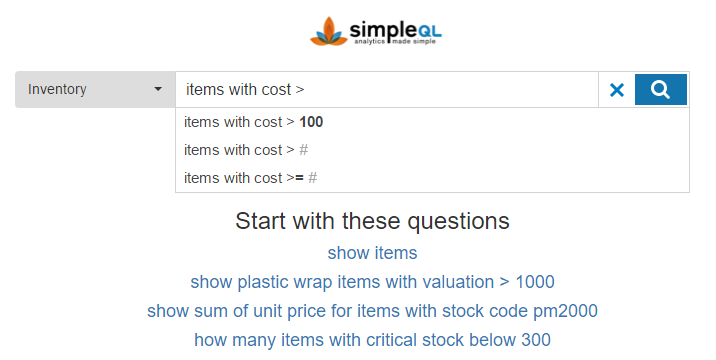
Some notable features (go here for the full list):
- Query interpretation: it constantly rephrases the query interpretation in grayed text right below user entry

- Middle-sentence suggestions: it supports modifying elements of the query in-place using the suggestion box
Other notable modern systems
Below some notable interfaces which are not strictly database-related, but still worth mentioning in this report:
Wolfram Alpha (2009)
Wolfram Alpha is the famous computational search engine developed by Wolfram Research. Users submit queries and computation requests via a text field. Wolfram Alpha then computes answers and relevant visualizations from a knowledge base of curated, structured data that come from other sites and books. It is able to respond to fact-based questions such as How old was Queen Elizabeth II in 1974?. It displays its input interpretation and results, see below:
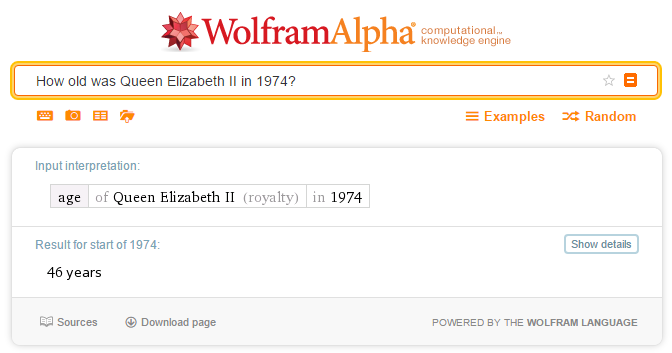
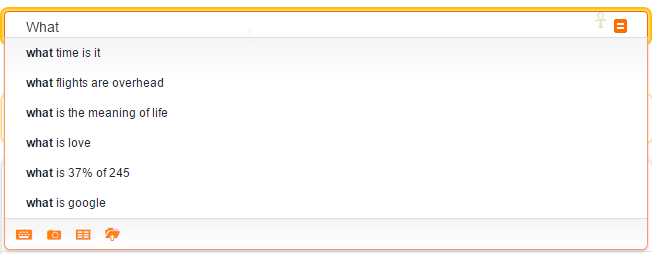
It also shows suggestions while typing, apparently from most frequent queries. Once starting to formulate natural language, these stop appearing, like in the example typing sequence below:



Wolfram Alpha does not answer queries which require a narrative response such as What is the difference between the Julian and the Gregorian calendars? but will answer factual or computational questions such as June 1 in Julian calendar.
For more details, check out this article on Stephen Wolfram’s blog, which presents its technology in relation to IBM’s Watson system (which won the Jeopardy contest). Wolfram Alpha is basically extracting a symbolic representation of the query to match to its curated database (whereas Watson in the deep tradition of information retrieval systems is based on statistics and similarity measures).
Interestingly, when accessing the site, numerous elements on the site allow exploring possibilities of the search, probably as a means to mitigate the empty prompt effect or “habitability problem”:

Quepy (2012)
Also worthy of mention is Quepy, a framework allowing implementation of NLIDB systems in python. It is based on the NLTK framework.


It allows query grammars with a dedicated DSL (domain-specific language). It also supports lemmatisation to allow for different words such as e.g. is, were, was, and uses part of speech tagging to define e.g. target in this case (optional determiner with noun in this example).

For more information
For more detailed information about NLIDB, their founding principles and history, a recommended read is Natural Language Interfaces to Database - An Introduction.